Abstract
Large Language Models (LLMs) have been shown to be capable of performing high-level planning for long-horizon robotics tasks, yet existing methods require access to a pre-defined skill library (e.g. picking, placing, pulling, pushing, navigating). However, LLM planning does not address how to design or learn those behaviors, which remains challenging particularly in long-horizon settings. Furthermore, for many tasks of interest, the robot needs to be able to adjust its behavior in a fine-grained manner, requiring the agent to be capable of modifying low-level control actions. Can we instead use the internet-scale knowledge from LLMs for high-level policies, guiding reinforcement learning (RL) policies to efficiently solve robotic control tasks online without requiring a pre-determined set of skills? In this paper, we propose Plan-Seq-Learn (PSL): a modular approach that uses motion planning to bridge the gap between abstract language and learned low-level control for solving long-horizon robotics tasks from scratch. We demonstrate that PSL achieves state-of-the-art results on over 25 challenging robotics tasks with up to 10 stages. PSL solves long-horizon tasks from raw visual input spanning four benchmarks at success rates of over 85%, out-performing language-based, classical, and end-to-end approaches.
Plan-Seq-Learn
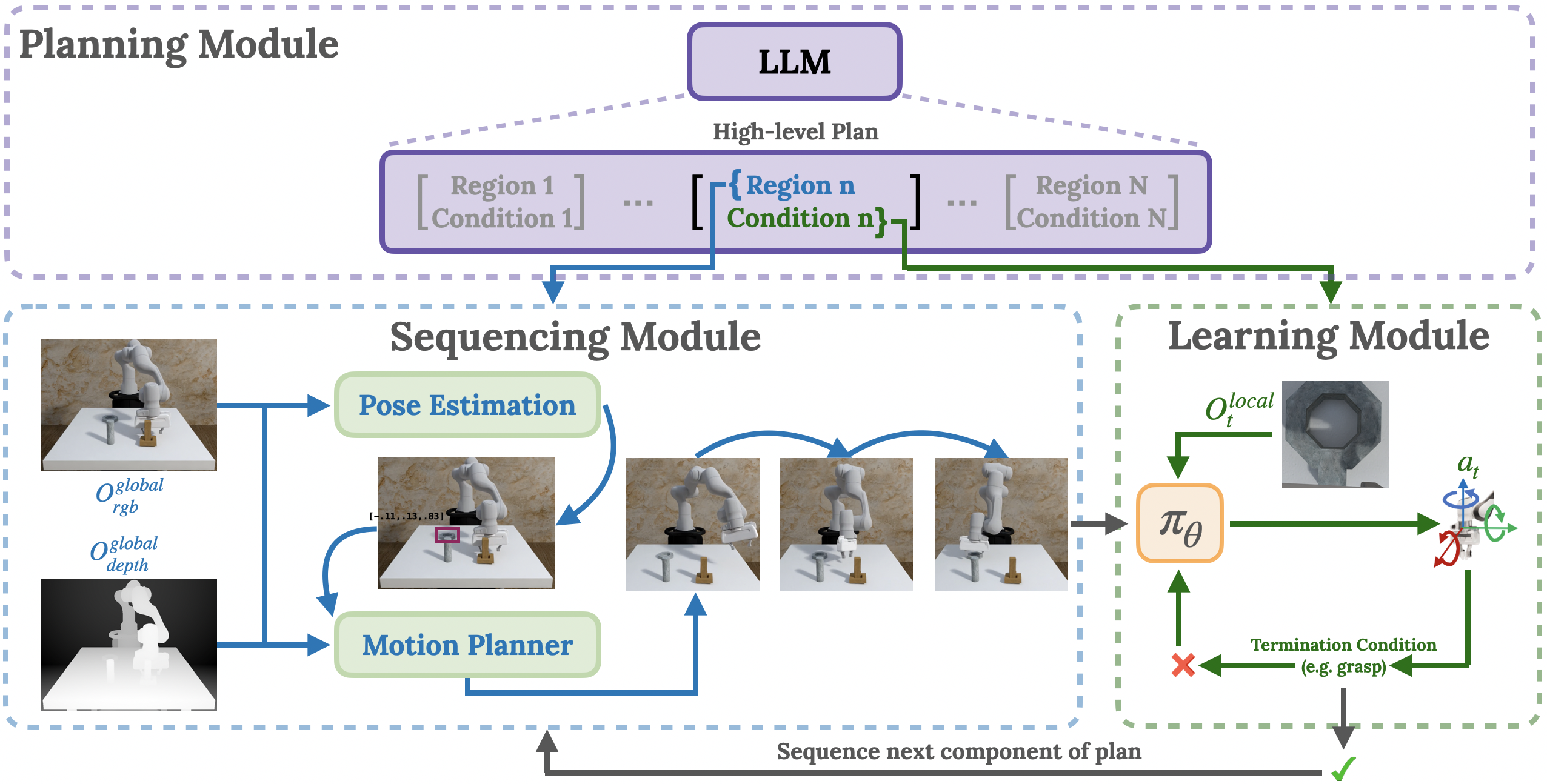
PSL decomposes tasks into a list of regions and stage termination conditions using an LLM (top), sequences the plan using motion planning (left) and learns control policies using RL (right).
PSL solves contact-rich, long-horizon manipulation tasks
RS-NutRound: 98%
RS-NutSquare: 97%
RS-NutAssembly: 96%
PSL solves long-horizon kitchen manipulation tasks with up to 10 stages.
K-Multistage-3: 100%
K-Multistage-5: 100%
K-Multistage-7: 100%
K-Multistage-10: 100%
PSL enables visuomotor policies to learn pick-and-place behaviors with 4 stages
RS-CanBread: 90%
RS-CerealMilk: 85%
PSL efficiently solves tasks with obstructions by leveraging motion planning
OS-Push: 100%
OS-Lift: 100%
OS-Assembly: 100%
BibTeX
@inproceedings{dalal2024psl,
title = {Plan-Seq-Learn: Language Model Guided RL for Solving Long Horizon Robotics Tasks},
author = {Dalal, Murtaza and Chiruvolu, Tarun and Chaplot, Devendra and Salakhutdinov, Ruslan},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2024},
}